
【K3S】15 - 其他三方组件简介

存储
Longhorn
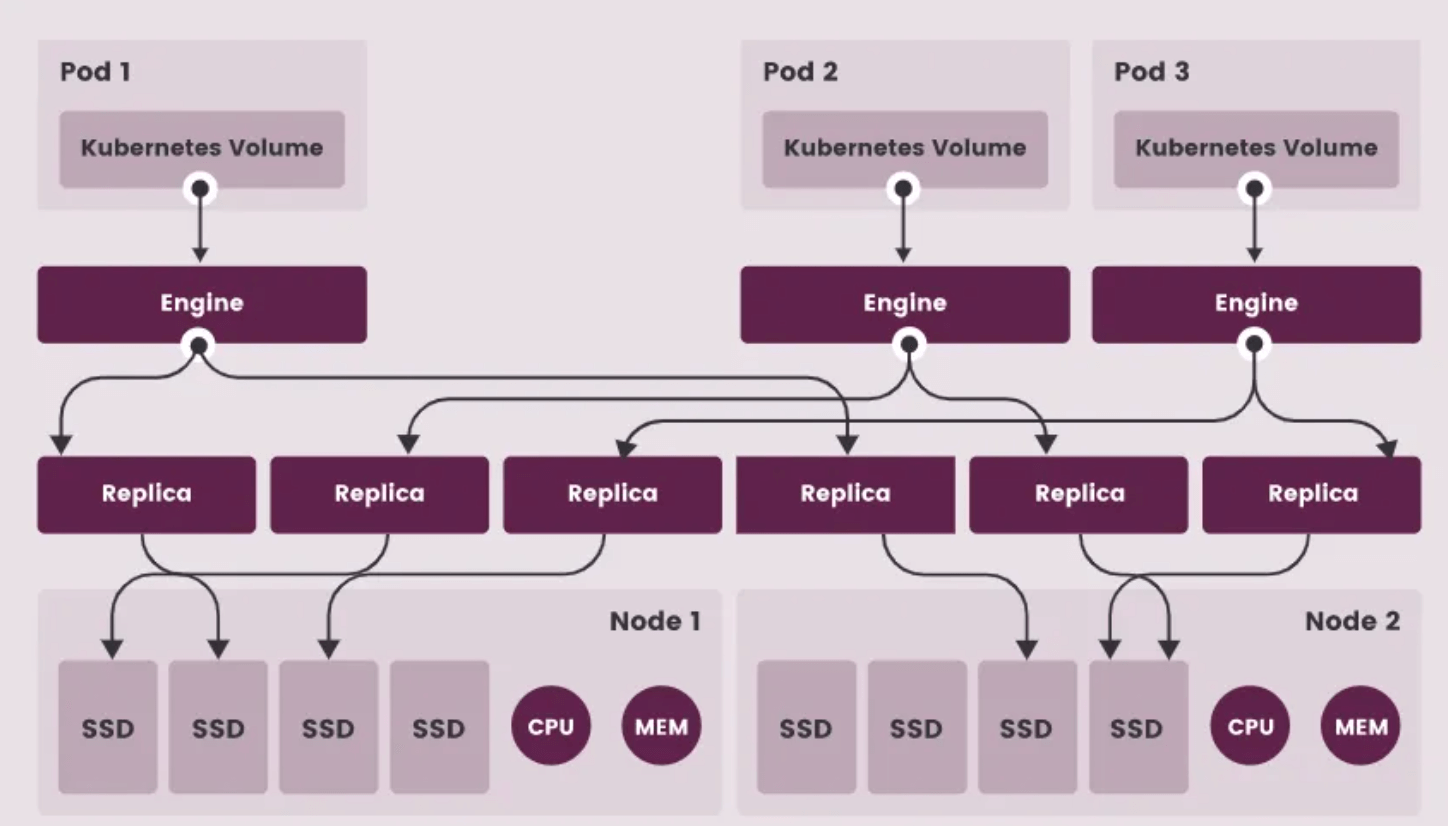
Longhorn是一个轻量级、可靠且功能强大的分布式块存储系统,适用于 Kubernetes。使用容器和微服务实现分布式块存储。Longhorn 为每个块储存设备卷创建一个专用的存储控制器,并在存储在多个节点上的多个副本之间同步复制该卷。存储控制器和副本本身是使用 Kubernetes 编排的。Longhorn 是免费的开源软件。它最初由Rancher Labs开发,现在作为云原生计算基金会的孵化项目进行开发。
优点 :
- 企业级分布式块存储,无单点故障;
- 支持增量快照和远程备份恢复(NFS/S3兼容对象存储);
- 定期快照和备份;
- 提供UI页面,管理方便;
教程:
- k8s持久化存储longhorn(安装篇) - 简书 (jianshu.com)
- https://zhangzhuo.ltd/articles/2022/05/19/1652929973831.html
现在我已经把mongodb和mysql的存储使用longhorn的classpath,只需要更改各个配置的存储部分即可,例如:
mongo.yaml:
1 | volumeClaimTemplates: |
因为mongodb我们建立的是副本集的模式,所以这里建议改为单副本模式,把副本的能力交给longhorn:
要注意的是,longhorn的副本节点之间,比较吃网络延迟,所以我使用m1和n1这两个节点,因为这两个节点处于同一内网,经测试,在使用低带宽的外网连接无法创建副本(表象是副本创建60秒就断开了,没有看到longhorn有配置此项,错误信息是grpc连接断开,所以猜测是wireguard的keepalive设置的太大了,应该减小此值,保证连接稳定,毕竟这几个节点之间的ping基本在10ms内,比官方测试的多副本下20ms数小)
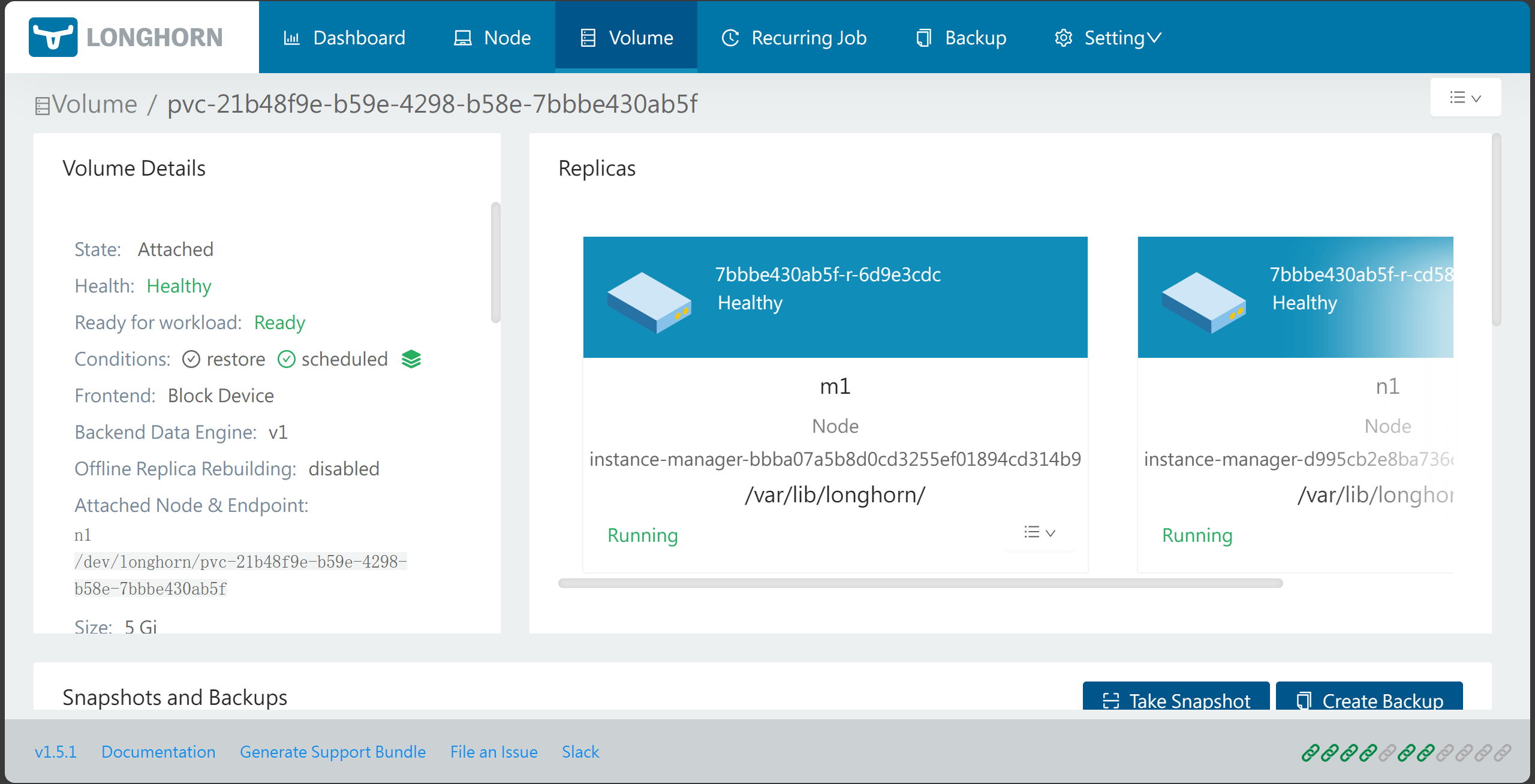
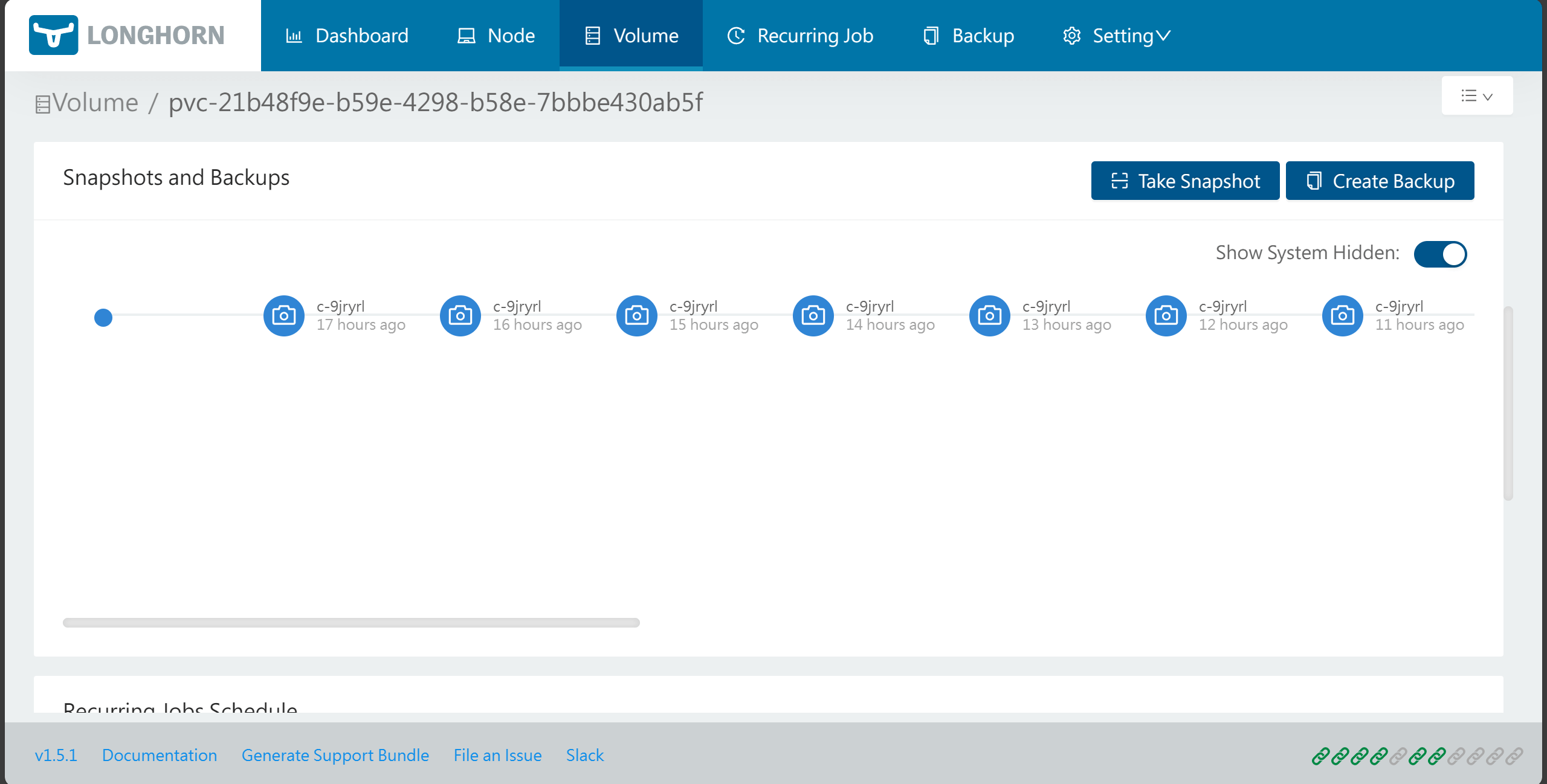
然后就可以设置自动快照,假如想恢复数据,需要先卸载pvc,再从Backup中恢复即可,因为恢复pvc时需要原来的名字,就必须先删除原来的pvc(longhorn创建的pvc里,回收策略是Retain)
数据库
TiKV
TiKV 是一个分布式事务型的键值数据库,提供了满足 ACID 约束的分布式事务接口,并且通过 Raft 协议保证了多副本数据一致性以及高可用。TiKV 作为 TiDB 的存储层,为用户写入 TiDB 的数据提供了持久化以及读写服务,同时还存储了 TiDB 的统计信息数据。它是由Rest语言编写的,而TiDB是由Go语言编写的
TiDB 和 TiKV 为什么是两个项目,因为它和 Google 的内部架构对比差不多是这样的:TiKV 对应的是 Spanner,TiDB 对应的是 F1 。F1 里面更强调上层的分布式的 SQL 层到底怎么做,分布式的 Plan 应该怎么做,分布式的 Plan 应该怎么去做优化。同时 TiDB 有一点做的比较好的是,它兼容了 MySQL 协议,当你出现了一个新型的数据库的时候,用户使用它是有成本的。大家都知道作为开发很讨厌的一个事情就是,我要每个语言都写一个 Driver,比如说你要支持 C++、你要支持 Java、你要支持 Go 等等,这个太累了,而且用户还得改他的程序,所以我们选择了一个更加好的东西兼容 MySQL 协议,让用户可以不用改。一会我会用一个视频来演示一下,为什么一行代码不改就可以用,用户就能体会到 TiDB 带来的所有的好处。
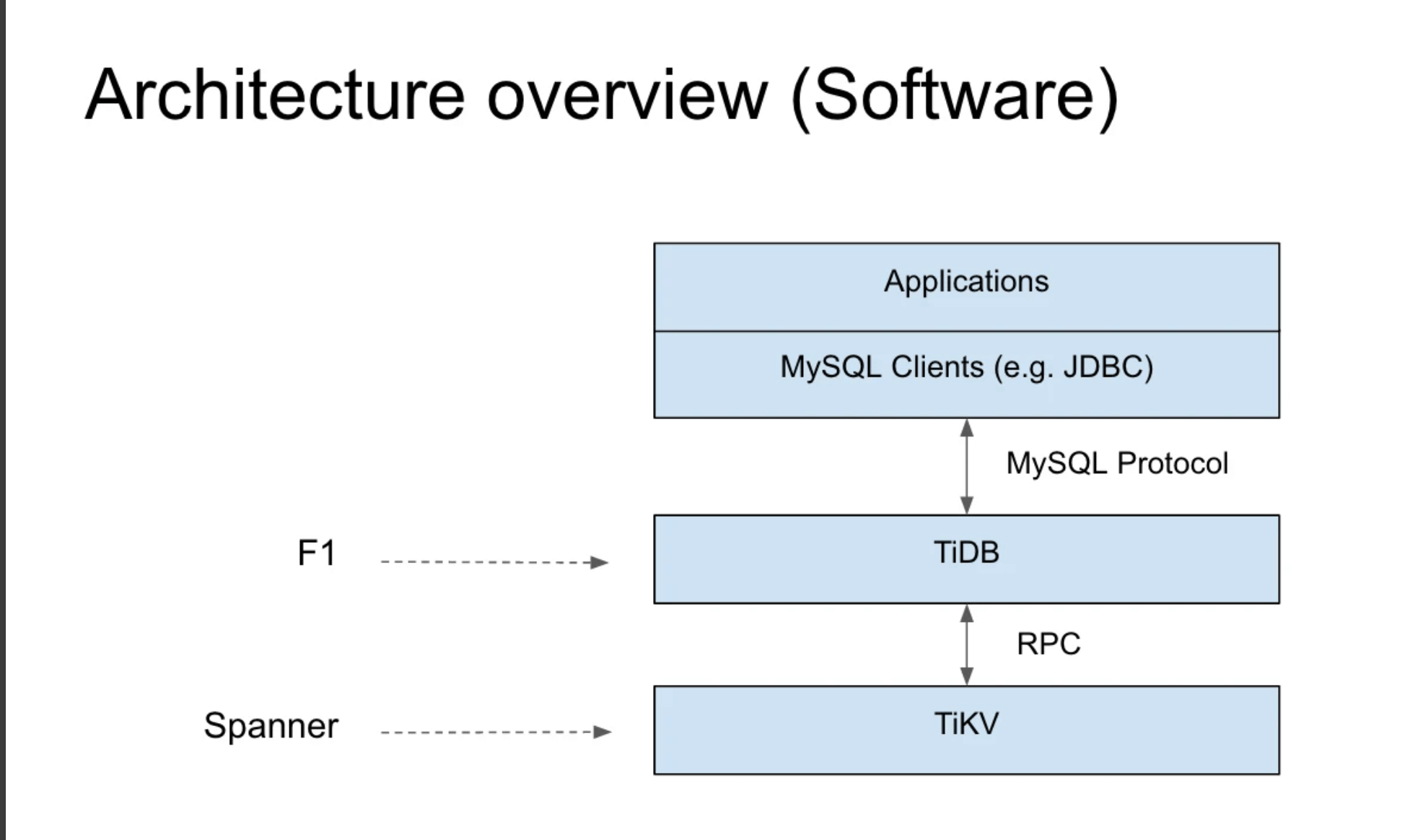
所以说为什么tidb的sql和mysql差不多,就是因为他们都使用了mysql的协议,因此这个协议如果你能手写,更换,是完全能做到插拔式的
参考:
流式消息

CloudEvents
CloudEvents 是一个以通用方式描述事件数据的规范。CloudEvents旨在大幅简化跨服务、跨平台的事件声明和投递。
事件无处不在。然而,事件生产者倾向于以不同的方式来描述事件。
缺乏通用的描述事件的方式意味着开发人员必须不断地重新学习如何消费事件。这也限制了类库、工具和基础设施在跨环境时发送事件数据的潜力,如SDK、事件路由器或跟踪系统等。我们从事件数据中实现的可移植性和生产力总体上受到了阻碍。
CloudEvents是一个用通用格式描述事件数据的规范,以提供跨服务、跨平台和跨系统的互操作性。
参考:
NATS
NATS是一个开源、轻量级、高性能的分布式消息中间件,实现了高可伸缩性和优雅的Publish/Subscribe模型,使用Golang语言开发。它采用了发布-订阅模型和请求-响应模型,并支持基于主题的消息路由。NATS具有低延迟、高吞吐量和可水平扩展的特点,非常适合用于构建微服务架构和事件驱动应用程序。
NATS消息传递支持在计算机应用程序和服务之间交换分段为消息的数据。这些消息由主题解决,不依赖于网络位置。这在应用程序或服务与底层物理网络之间提供了一个抽象层。数据被编码并构成消息并由发布者发送。该消息由一个或多个订户接收,解码和处理。
NATS使程序可以轻松地跨不同环境,语言,云提供商和内部部署系统进行通信。客户端通常通过单个URL连接到NATS系统,然后订阅或发布消息给主题。通过这种简单的设计,NATS允许程序共享公共消息处理代码,隔离资源和相互依赖性,并通过轻松处理消息量的增加进行扩展,无论是服务请求还是流数据。
NATS核心提供最多一次的服务质量。如果订户没有收听主题(没有主题匹配),或者在发送消息时未激活,则不会收到消息。这与TCP / IP提供的保证级别相同。默认情况下,NATS是一种即发即弃的消息传递系统。如果您需要更高级别的服务,您可以使用NATS Streaming或通过经过验证的可扩展参考设计为客户端应用程序构建额外的可靠性。
Apache Pulsar是一个开源的分布式消息传递平台,具有高可靠性、可扩展性和低延迟的特点。它使用发布-订阅模型,支持多租户、多数据中心部署,并具有强大的持久化和数据复制功能。Pulsar还提供了灵活的消息传递语义,如准确一次性传递(Exactly-Once Delivery)和At-Least-Once Delivery。
Apache Pulsar的架构基于分层的设计,包括Broker层、BookKeeper层和ZooKeeper层。这种架构使得Pulsar具有良好的可伸缩性和故障恢复能力。相比之下,NATS采用了简单的中心式架构,没有复杂的依赖和组件,使得它非常易于部署和使用。
在性能方面,Apache Pulsar具有出色的吞吐量和低延迟,特别适用于大规模的消息传递场景。NATS在轻量级和快速性方面表现出色,对于中小规模的应用程序非常适用。
应用构建与镜像打包

Helm
Helm 是 k8s 的包管理工具,类似 Linux 系统常用的 apt、yum 等包管理工具。使用 helm 可以简化 k8s 应用部署。
每个包称为一个 Chart,一个 Chart 是一个目录(一般情况下会将目录进行打包压缩,形成 name-version.tgz 格式的单一文件,方便传输和存储)。
对于应用发布者而言,可以通过 Helm 打包应用,管理应用依赖关系,管理应用版本并发布应用到软件仓库。
对于使用者而言,使用 Helm 后不用需要了解 Kubernetes 的 Yaml 语法并编写应用部署文件,可以通过 Helm 下载并在kubernetes上安装需要的应用。
除此以外,Helm 还提供了kubernetes上的软件部署,删除,升级,回滚应用的强大功能。
Backstage
Backstage 是一个开源的前端应用程序框架,用于构建内部工具、管理界面和管理面板。它由 Spotify 公司开发,并在2020年开源。
Backstage 的主要作用是为开发团队提供一个统一的平台,用于构建、部署和管理内部工具和服务。它的设计理念是将公司内部的各种工具、服务和信息集中在一个统一的界面中,以提高开发团队的效率和协作。
以下是 Backstage 的主要作用和特点:
- 统一的界面:Backstage 提供一个统一的用户界面,将各种工具、服务和信息集成到一个可定制的仪表板中。开发团队可以在同一个界面中访问和管理各种工具和服务,提高工作效率。
- 可插拔的架构:Backstage 的架构是可插拔的,允许开发团队根据自己的需求和要求定制和扩展功能。它提供了丰富的插件系统,使开发团队可以轻松添加和集成新的功能和服务。
- 统一的数据源:Backstage 可以集成各种数据源,如代码仓库、CI/CD工具、故障监控等,将数据聚合并展示在统一的界面中。这样,开发团队可以更方便地查看和分析数据,快速做出决策。
- 自动化工作流:Backstage 提供了自动化的工作流功能,可以帮助开发团队简化和加速常见的任务和流程。例如,自动化的部署流程、自动化的测试流程等,使开发团队能够更高效地工作。
- 多团队协作:Backstage 支持多团队协作,每个团队都可以有自己的定制化界面和功能。它提供了权限管理和团队间的共享功能,使不同团队能够在同一个平台上协同工作。
BuildPack
BuildPack是一个程序,它能将源代码转换成容器镜像的并可以在任意云环境中运行。通常 buildpack 封装了单一语言的生态工具链。适用于 Java、Ruby、Go、NodeJs、Python 等。
它主要有两部分组成 builder 和 buildpack。builder 是执行构建的运行镜像, buildpack 是构建的工作单元。
builder 包含了构建所需要的所有组件和运行环境的镜像。一般使用官方提供的 builder 就可以满足大部分编译场景,如果有特殊需要 builder 也可以自己生成。
通过编写 builder.toml 文件,配置 基础镜像(build image + run image)、build 执行周期(lifecycle)、 构建工作单元(buildpack) 可以构建一个 builder 镜像。
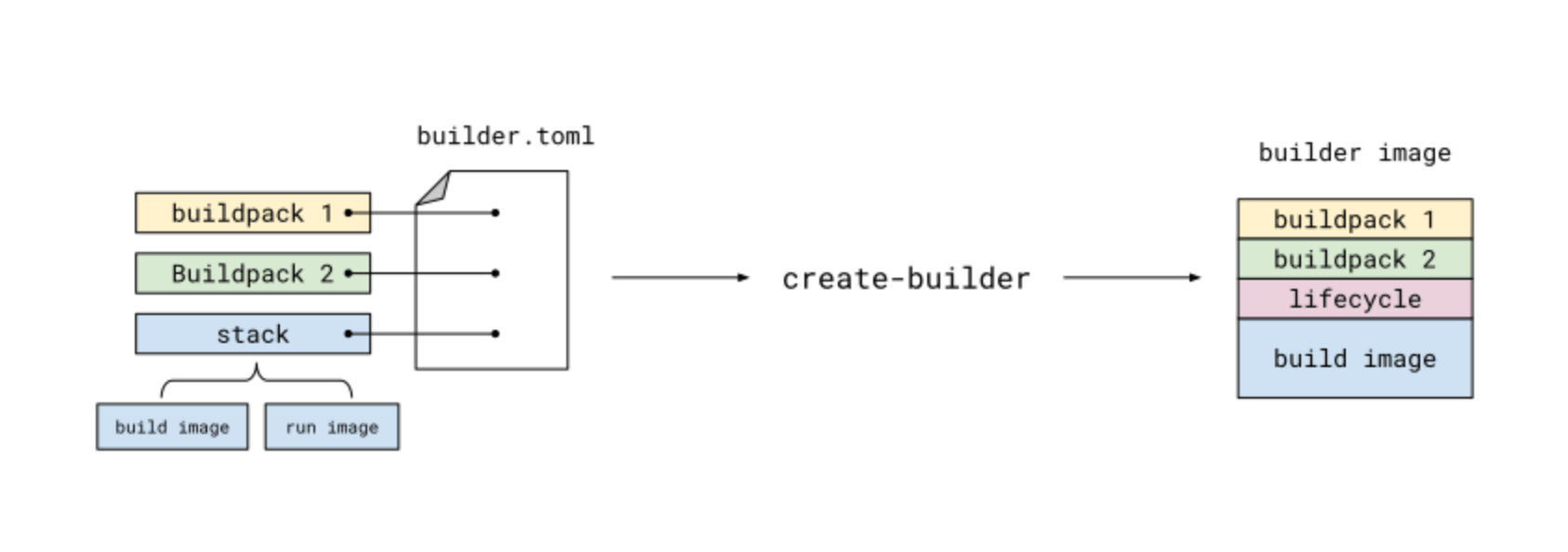
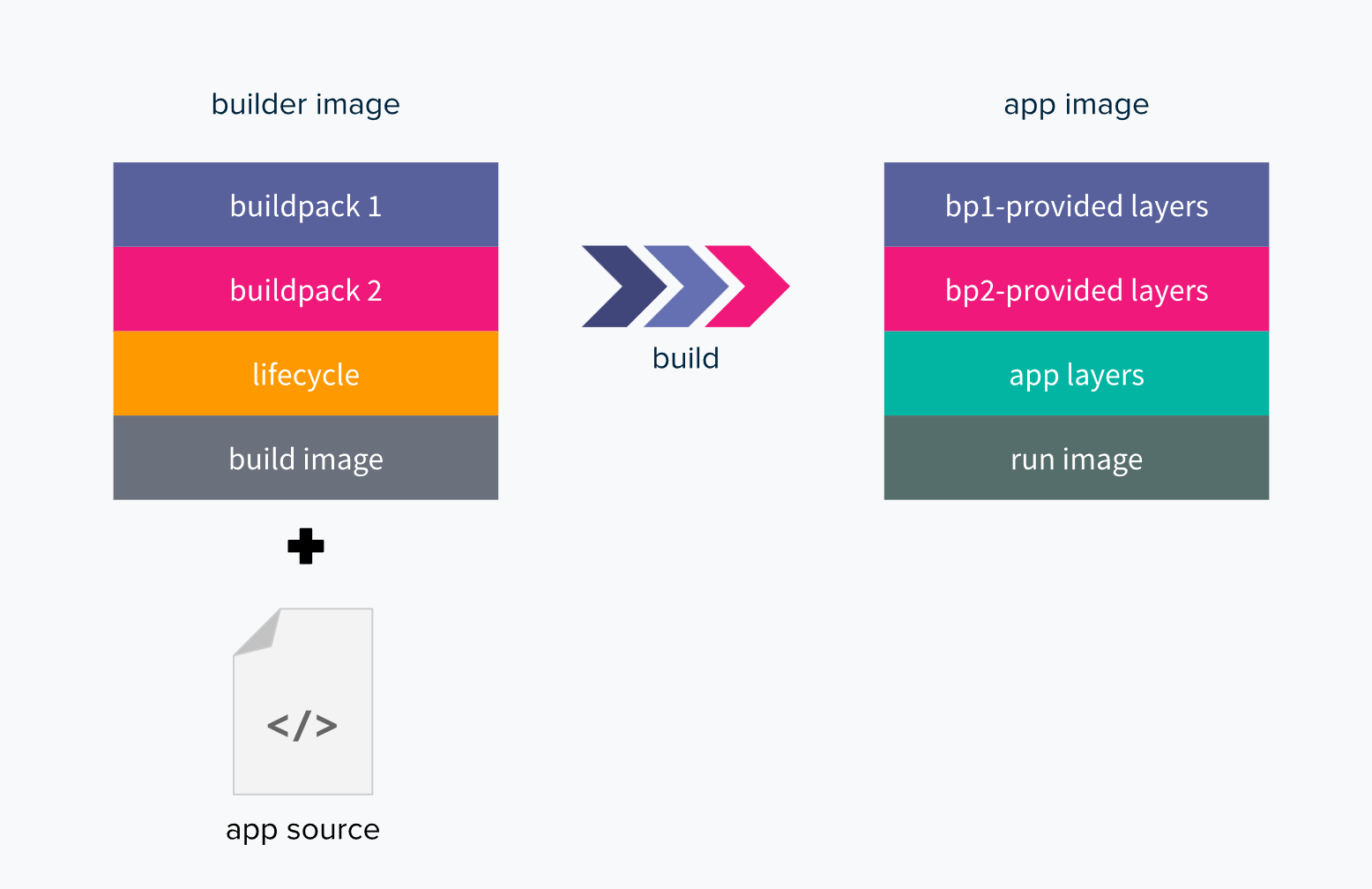
buildpack 包含了一系列构建步骤。一般包括 检查程序源代码、构建代码、生成镜像等。
例如官网建议的 builder:”heroku/buildpacks:18” 中提供了多达 9 种语言的 buildpack
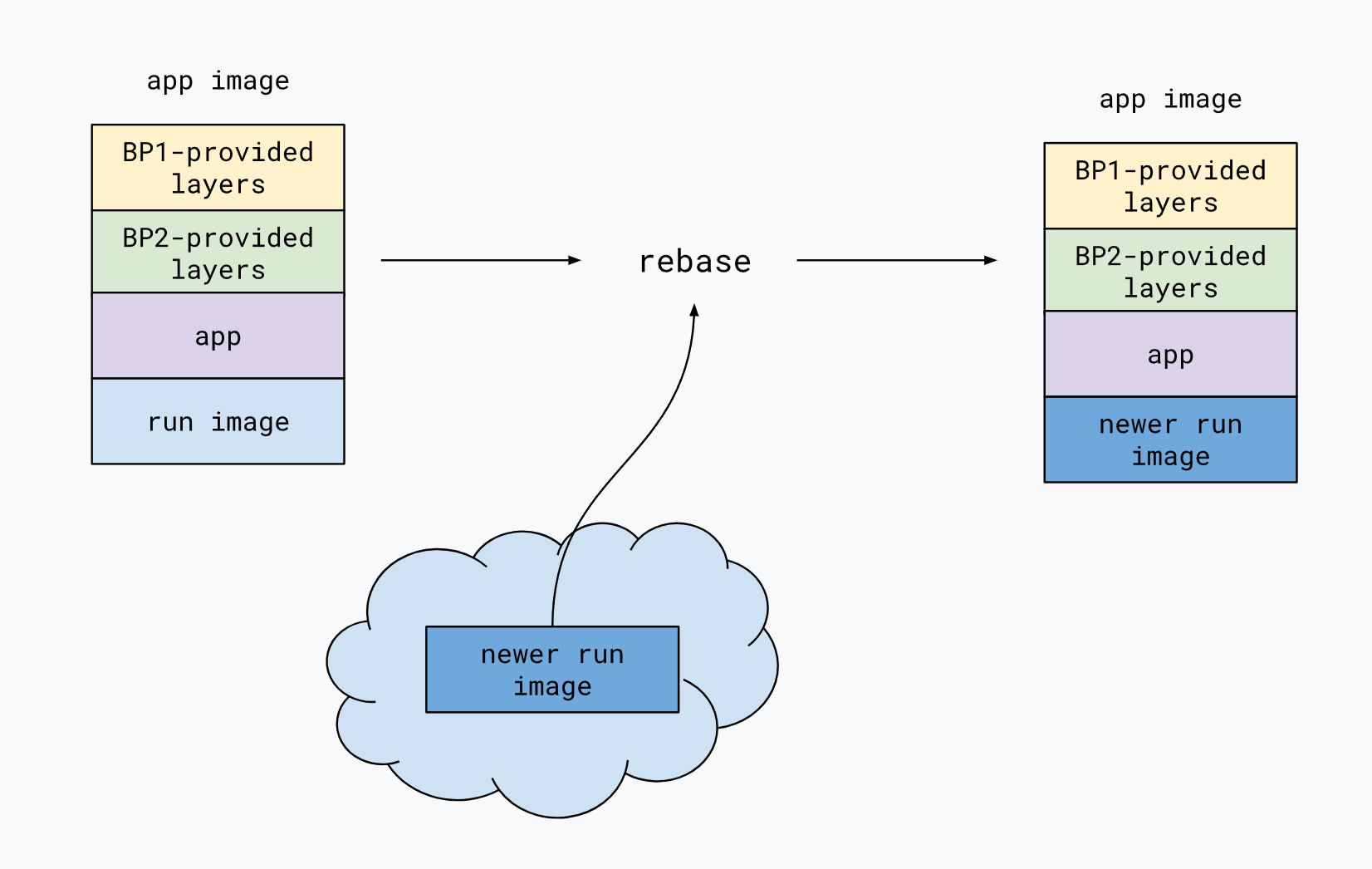
rebase 允许应用程序开发人员在 run image 发生更改时快速更新镜像。通过使用 rebase,此命令避免了完全重建程序。
参考:
KubeVela
KubeVela 是一个面向平台构建者的、简单易用但又高度可扩展的云原生平台构建引擎。
具体来说,KubeVela 的目标是让任何平台团队都能够以 Kubernetes 原生的方式,快速、高效的打造出适合不同业务场景的、能够直面用户的云原生平台出来。比如:构建应用 PaaS、数据库 PaaS、AI PaaS 或者持续交付系统等
KubeVela 通过以下设计,使得面向混合/多云环境的应用交付变得非常简单高效:
- 完全以应用为中心 - KubeVela 创新性的提出了 开放应用模型(OAM)来作为应用交付的顶层抽象,并通过声明式的交付工作流来捕获面向混合环境的微服务应用交付的整个过程,甚至连多集群分发策略、流量调配和滚动更新等运维特征,也都声明在应用级别。用户无需关心任何基础设施细节,只需要专注于定义和部署应用即可。
- 多环境/多集群交付 - KubeVela 原生支持多环境/多集群两个维度的混合应用交付,帮助用户大大降低了多集群分布式应用的云原生交付门槛。
- 基础设施无关 - KubeVela 是一个完全与运行时基础设施无关的应用交付与管理控制平面。所以它可以按照你定义的工作流与策略,面向任何环境交付和管理任何应用组件,比如:容器、云函数、数据库,甚至网络和虚拟机实例等等。
- 应用交付工作流 - KubeVela 的交付模型是利用 来实现的。CUE 是一种诞生自 Google Borg 系统的数据配置语言,它可以将应用交付的所有步骤、所需资源、关联的运维动作以可编程的方式粘合成一个 DAG(有向无环图)来作为最终的声明式交付计划。相比于其他系统的复杂性和不可扩展性,KubeVela 基于 CUE 的实现不仅使用简单、扩展性极强,也更符合现代 GitOps 应用交付的趋势与要求
参考:
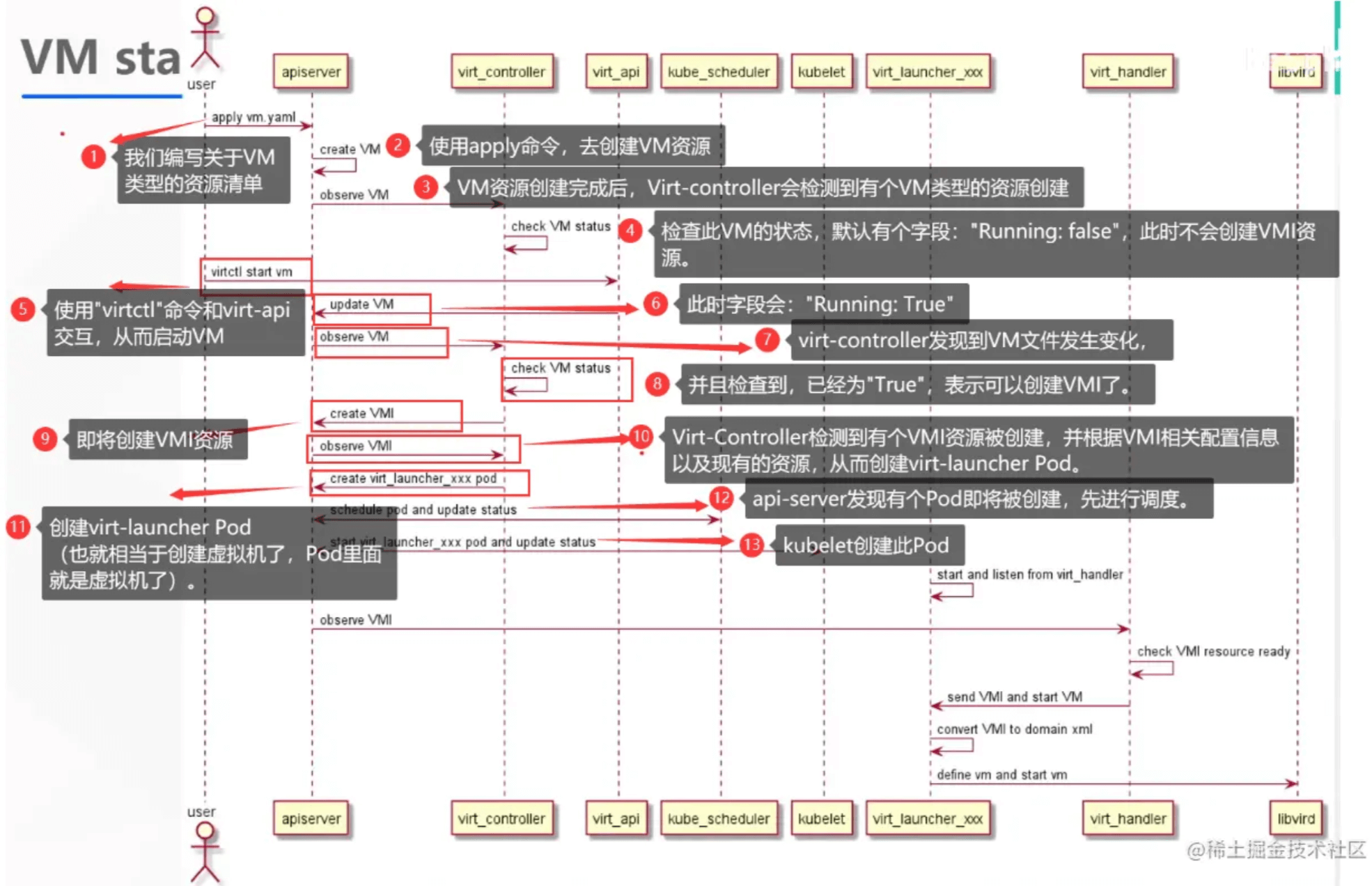
KubeVirt
Kubevirt 是Redhat开源的以容器方式运行虚拟机的项目,以k8s add-on方式,利用k8s CRD为增加资源类型VirtualMachineInstance(VMI), 使用容器的image registry去创建虚拟机并提供VM生命周期管理。 CRD的方式是的kubevirt对虚拟机的管理不局限于pod管理接口,但是也无法使用pod的RS DS Deployment等管理能力,也意味着 kubevirt如果想要利用pod管理能力,要自主去实现,目前kubevirt实现了类似RS的功能。 kubevirt目前支持的runtime是docker和runv。
它有如下用处:
- 利用 KubeVirt 和 Kubernetes 来管理虚拟机
- 一个平台上将现有的虚拟化与容器化打通并管理
- 支持虚拟机应用与容器化应用实现内部交互访问
参考:
Operator Framework
引用官网的话,“An Operator is a method of packaging, deploying and managing a Kubernetes application.” Operator是一种打包、部署、管理K8S应用的方式。
很明显,Operator天生就是面向交付及运维的。在常见的环境中,对于无状态的K8S应用,借助于容器的健康检查机制通过自启可以解决绝大部分问题(虽然一定程度上也掩盖了自身确实存在的问题),对这些应用,使用Operator的必要性不足,所以通常的Operator,都是针对于有状态应用/中间件来做具体实现的
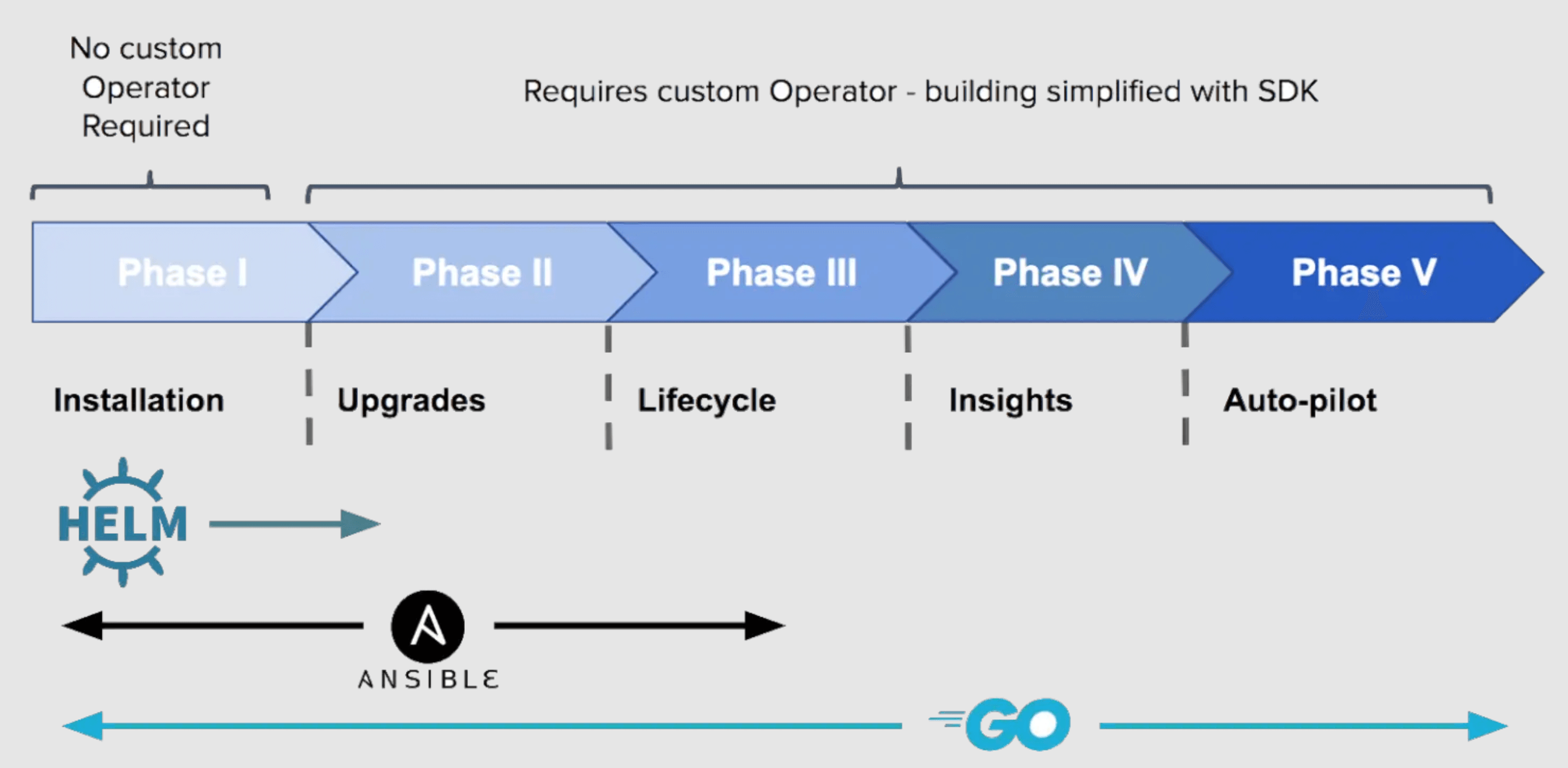
在传统运维环境中,中间件都是基于非容器部署,我们往往会面对各种部署及运维需求:
- 备份&数据恢复。备份分为冷备和热备。冷备通常可以通过定时任务执行,对于即时的备份需求,大公司内部往往有成熟的平台支撑,但中小企业往往是运维人员手动执行操作,数据恢复也是如此
- 扩容。又分scaleup、scaleout。对于数据库,如果只是scaleout,增加从节点,相对较容易;但是如果是scaleup,升级主节点cpu、内存呢?往往涉及比较复杂的一系列运维操作,且风险极大
- 故障恢复。对于特定中间件,通常都有比较成熟的高可用集群部署方案,但对于运维而言,依然存在诸多问题。对于异常节点,如何恢复?对于不同中间件之间的依赖,如何处理?(比如断电重启中,hadoop对zk的依赖,hbase对hadoop的依赖等)
- 声明式部署。对于POC环境,单节点即可;对于生产环境,使用集群方式,节点数多少等等,都使用声明式地配置,通过helm/ansible方式一键安装
- 安全。网络访问限制、加密协议及秘钥管理等
- 版本升级。如何平滑升级,一直是部署运维人员面对有状态系统头疼的问题,所以通常这些系统比较稳定,一方面是自身问题,另一方面是升级困难风险高,不得不压住升级需求。
以上场景都是可以通过Operator解决,使用方式上,只需要创建指定格式的K8S CRD即可,至于Operator内部如何执行具体的部署/运维逻辑,交付人员无需关心。